
AI/ML Papers I read in 2024ish that I liked
A list of papers and other writings from the last year that influenced me

As this is a newsletter on AI/ML across the geosciences I thought that I should periodically review some of the literature that might be interesting to a wide variety of researchers that think about things that Njord Centre researchers think about. This list is non-exhaustive and mostly culled from my #things-to-read slack channel for my research group slack. It doesn’t really only include papers from 2024, but rather, papers I have read since the beginning of 2024 that have informed my view on physics, science, AI/ML, etc. In any case the titles are all linked to the papers so feel free to read them and discuss!
Model scale versus domain knowledge in statistical forecasting of chaotic systems
William Gilpin. Physical Review Research, 2024.
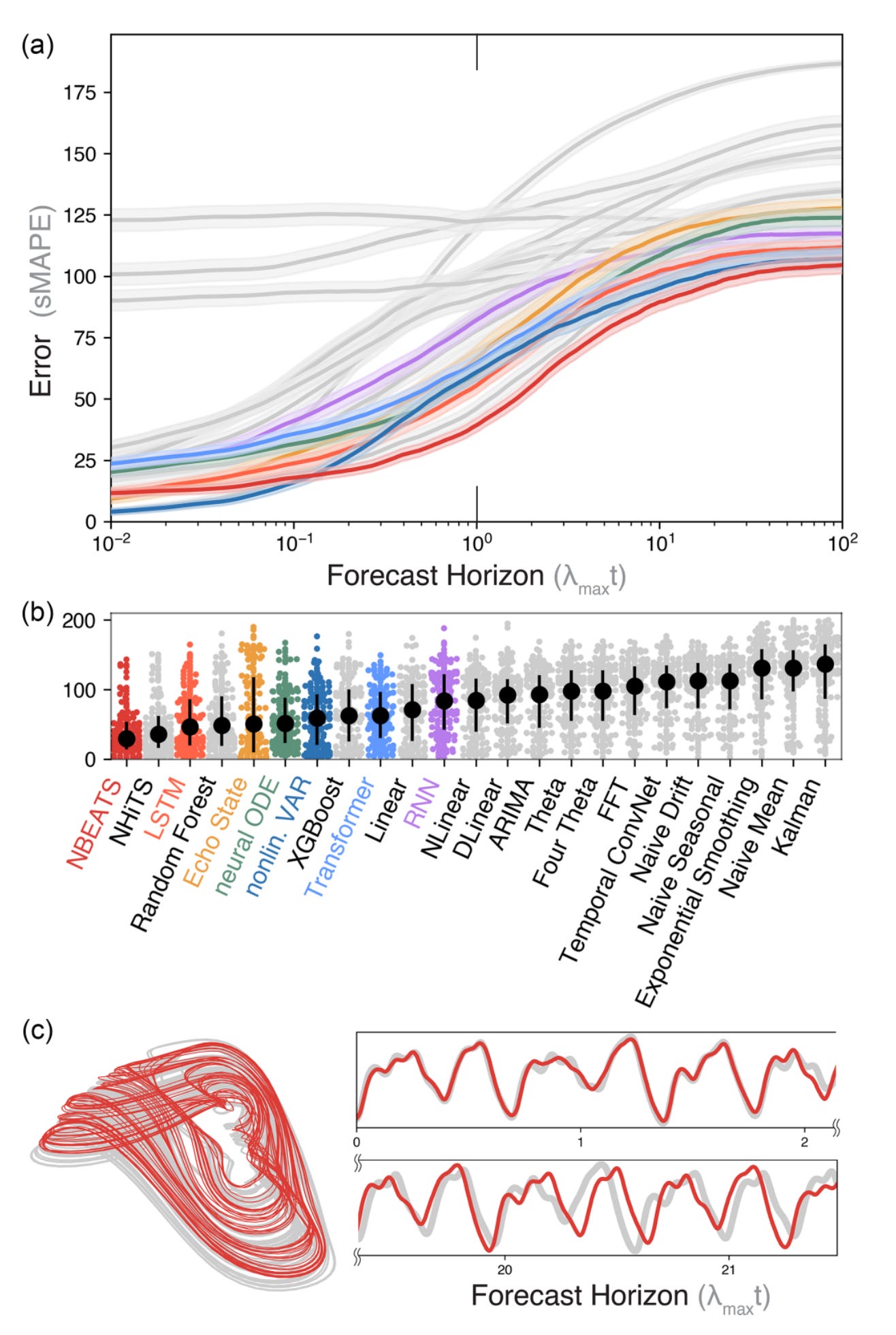
This paper, above most others, had a huge impact on me in 2024. Basically it presents a huge number of chaotic systems and demonstrates that machine learning methods (particularly NBEATS) are able to forecast further into the future than previously though possible. It also serves as the example in my previous post about writing good code for publications. Moreover, this paper suggests that there may be both methodological issues in how we characterize the predictability of systems, that is, we could be leaving some of what we know on the table when we are attempting to assess how chaotic a system is and when we should give up trying to predict it into the future. This paper was so influential that I invited William to give one of the plenary lectures at the 2024 Exploring System Dynamics with AI meeting at the University of Oslo Science Library. You can watch his lecture here.
Predictability: a way to characterize complexity
G. Boffetta, M. Cencini, M. Falcioni, A. Vulpiani. Physical Reports, 2002.
This paper is one of several of a collection of literature that discusses how chaos and complexity can also be described as data compression. That is, how chaos theory can be described using dynamical systems theory, entropy, and information theory.
A well ordered system such as
can be compressed exactly into a very small description. Why is this true? Because after one cycle we already can repeat all cycles as time goes to infinite. Therefore we need very little observation of the signal itself to predict it into the future. However, a chaotic system (i.e., has a positive Lyapunov exponent and therefore different initial conditions create exponentially diverging trajectories) cannot be treated this way. This is because as time progresses the uncertainties grow too fast for us to have a regular way to predict into the future. But what this means is that if we are to find efficient ways to predict the future we should find ways the efficiently compress the data we have so that it uncompresses without loss. Why should earth scientists care about data compression? Neural networks, in many cases, are a form of data compression. It is perhaps, trivially true that compression is an important component as to why neural networks are good at their jobs as they are able to efficiently organize data from latent spaces into meaning (i.e., prediction).
The Bitter Lesson
Rich Sutton
This is a blog post and not a paper, but I think it is as equally important as any paper. It basically sums up all of the current literature on AI/ML research as this: having generalized models, with modular structures that leverage computational power (i.e., more CPUs, GPUS, whatever-PUs) will lead to further development in any kind of statistical learning problem. This should be true for any kind of learning, not just for chatGPT type problems but also any geophysical problem. From a physics point of view this makes sense, we don’t have a huge selection of algorithms that describe electrodynamics, we have maxwell’s equations (as an example). What this lesson implies is that, all things being equal with access to data, having more computational power is the limiting factor on our ability to compute complex things. I like to couple this idea with a decades old paper from Microsoft Research which says, all things being equal, models of varying complexity arrive at the same result where accuracy of that result increases somewhat less than exponentially as model data increases exponentially.
Seismic events miss important kinematically governed grain scale mechanisms during shear failure of porous rock
Alexis Cartwright-Taylor, et al. Nature Communications

This paper isn’t about machine learning but I quite like it’s premise. Essentially, stress can elastically reorient within the rock through grain boundary rotations which could be why acoustic emission data (i.e., seismology) does not capture the entire stress history of faults. While this is an experimental paper, there is no reason to expect such conclusions do not apply to nature, and thus, we are left wondering what the true energy budget of a natural fault must look like if that energy budget is governed by a host of processes other than friction and fracturing.
Universal differential equations for glacier ice flow modelling
Jordi Bolibar, et al. Geoscientific Model Development
There are different paradigms when it comes to combining physics and machine learning (this is worthy of it’s own post I think). One paradigm is to treat your geophysical problem it as a statistical problem. This has a lot of advantages as it allows you to focus on data-driven discovery of complex relationships using data sets that have been gathered while not getting bogged down in trying to physically model a complex system. It also is great when these systems are so complex, they might not be able to be physically modeled. Another paradigm is a physics informed neural network. In this mode, you treat the neural network as the solver, and constrain it by training the network on initial and boundary conditions using a loss function represented by known physics. This allows for a lot of benefits to the modeler as it typically gives you a meshless estimator and can be trained in the fraction of a time of a traditional computational method. However, this can be tricky to escape a numerical setting and train on real world data depending on the topic. Universal differential equations instead use neural networks to replace the parameterization of a known system. In the case of this paper, they attempt to parameterize the spatial variability of glaciers from different climates. Each method has it’s positives and negatives. But added together, it makes me wonder if these methods sit on the spectrum between the two statistical cultures as noted by Leo Breiman. That is, do we assume that the mechanism that generates our data is known, i.e., it is some physical law, or do we assume that the mechanism is perhaps too complex and can only be estimated? This I think is a spectrum of what can be measured and is not an either/or kind of situation.
Conclusion
I am sure I have read other papers. There are perhaps, too many papers to read. Feel free to send me papers you think would be fun to discuss here. Also feel free to send me topics you would like to be discussed here.