
What Spectroscopy Was to the 1800s, Embeddings Are to Science Now

I can’t find it which is a shame, but there was a comment on hacker news in response to a blog that was posted that was describing something about how AI agents are going to change your life. And that comment said something to the effect of:
I am getting rather tired of reading blogs about how AI is going to change everything.
I can appreciate that sentiment.
Anyways, this substack is going to be about how embeddings are not merely computational tools but represent a new methodology for examining complex systems that may reveal structures beyond our current theoretical frameworks.
A year and a half ago I organized a conference called Exploring System Dynamics in the Natural World with AI along with Thorsten Becker (thanks Thorsten!). This conference was motivated by me reading various papers across the topics of chaos, geophysics, information theory, and AI. The idea behind the conference was two fold. First, most AI for science discourse focuses on engineering improvements (faster weather models, better protein folding) rather than fundamental questions about what these models reveal about nature itself. These are laudable goals and should be pursued. However, I wanted to better understand why neural networks were becoming so good at understanding complex physical systems which I talked about in my intro talk that you can watch here:
Second, I set the goal of considering this idea broadly and asked people who thought about it from the theoretical development of methods, people who thought about it from a physicist point of view, but also industry and education. You can watch most of the lectures from the conference here. Together it seemed that we could construct some explanations as to why neural networks can predict chaos better, make better weather predictions, and do all sorts of other things. But today, a year and half later, I have even more questions. But I think I will need to start from the beginning of the talk above until now to explain everything.
To put it simply, everything started because this paper by William Gilpin fascinated me. In it he demonstrates that neural network-based predictors are able to capture chaotic dynamics further into the future than theoretically thought possible. From the abstract:
We find that large-scale, domain-agnostic forecasting methods consistently produce predictions that remain accurate up to two dozen Lyapunov times, thereby accessing a long-horizon forecasting regime well beyond classical methods. We find that, in this regime, accuracy decorrelates with classical invariant measures of predictability like the Lyapunov exponent.
This is profound. It tells us that our understanding of what is predictable and what is unpredictable may not be as well rounded as we thought. And so I decided to dive deeper (I feel like this is a phrase I learned chatting with LLMs). What is it that neural networks are doing when they are modeling these systems? Why might they be better at these kinds of predictions in comparison to traditional methods and the theory that dictates them? I think one way to think about it is to consider what happens when you put data into an autoencoder.
Variational Autoencoders
There is plenty written about variational autoencoders that doesn’t need to be reiterated here. But just in case, I will give some background. The main point of a variational autoencoder is to learn the parameters mu and sigma that describe the distribution of the latent space z.
. As a generative model, the basic idea… | by Roger Yong | Geek Culture | Medium")
It learns these by encoding the input data x, by passing the data through one or more neural network layers (these can be linear, convolutional, whatever) until this is “compressed” into the latent space. This compression can happen both by reducing the dimensionality or by expanding it (sometimes it may be better to train a large model than a small one). This latent space is then passed to the decoder, which mirrors the encoder, and produces xhat (right in diagram above), which is the reconstruction of the training data x (left in diagram above). If xhat approximates x, (e.g., it recreates the training images well, you have R2 scores greater than 0.9, etc.), then you have, at least a first pass of a model that can construct a latent space that may capture all of the interactions of the system of study. This latent space, which is also called an “embedding”, can then be used as features for new models such as being clustered to try and find some structure that could be informative for a task or used in some kind of supervised learning (e.g., separating cat and dog pictures). Because these latent features are described by probability distributions, you can sample these distributions and generate new data from them. The important component here is to understand the concept that neural networks construct a latent embedding space that attempts to capture all of the interactions that could be used to describe the system you are studying whether that is images of cats, language, or a chaotic time series. The architecture can then become arbitrarily complex.
These latent spaces can then be used to do all sorts of things and here is a non-exhaustive list of abilities:
show the motion of atmospheric components taken from this linkedin post where they trained neural network based weather simulators:
Or you could use it to understand what kind of topics do AI labs publish on like I did in this substack I wrote a while ago:

Or you could use it to map everything like google’s AlphaEarth Foundation model which compresses petabytes of satellite data (optical imagery, radar, climate models, topography, gravity measurements) into 64-dimensional embeddings for every 10-meter square of Earth’s terrestrial surface.
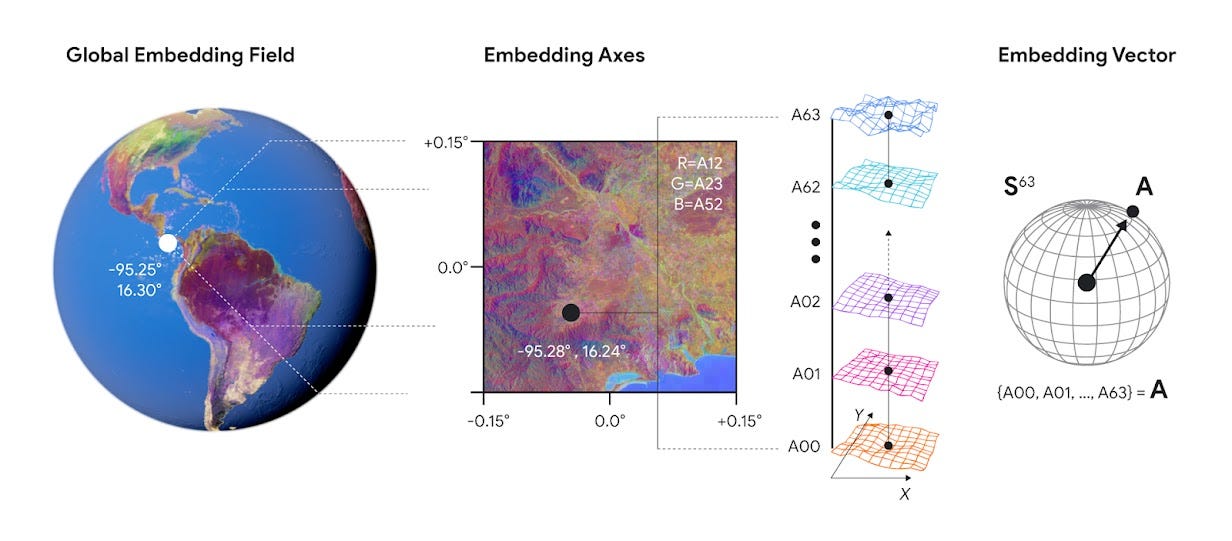
The AlphaEarth model doesn’t “know” about geology, hydrology, or agriculture explicitly. Yet researchers are using these embeddings to predict crop yields, track deforestation, and map wetland vegetation with higher accuracy than purpose-built remote sensing models.
To put it a different way, neural networks are able to understand complex geometries that define how to separate latent non-dimensional spaces that can motivate decisions that humans cannot conceive quantitatively (e.g., what exactly is the boundary of a topic) where decision is defined as determining the outcome based on the input.
So far this seems reasonable. You could even call this principal component analysis on steroids. but where it gets really wild is when you introduce the “Platonic Representation Hypothesis”. The Platonic Representation Hypothesis is from an 2024 ICML paper where they claim that:
Neural networks, trained with different objectives on different data and modalities, are converging to a shared statistical model of reality in their representation spaces.
And this isn’t just claimed in this position paper, we see evidence of this from different comparisons as well. For example, in this paper, the authors argue that they can train models that can translate between two incomparable language models by using the embeddings from one model to predict the other.

This has a profound implication. First translating from an unknown vector space into a known vector space means you can probably reconstruct at least some of the original training data which means you could reveal the secrets an unknown model knows by examining it’s embeddings as long you have a known model to compare it to. But this also means that this latent representation is shared between the two models even when the original model is unknown.

To provide an analogy to something from the history of science, embeddings might be to 21st-century science what spectroscopy was to 19th-century science. A technique that reveals structure invisible to direct observation, enabling discoveries that reshape entire fields.

When Fraunhofer observed absorption lines in the solar spectrum (above you can see first an example of the sun’s absorption and second an example of the sodium absorption spectra), he had no theory to explain them. But even without a physical explanation it was something obvious to study and eventually was a fundamental observation that led to quantum mechanics. Similarly, embeddings reveal patterns in high-dimensional data that we lack theoretical frameworks to fully explain, but the patterns are demonstrably real (they generalize, predict, transfer across domains). And so the question arises why do these vector spaces connect? Or to quote from the platonic representation paper itself:
if there is indeed a platonic representation, then finding it, and fully characterizing it, is a research program worth pursuing.
To put it a different way, if these embedding vectors can be translated between themselves, and thus are converging to a shared state of reality, then what we have here is not some sort of “black box” but actually a tool that allows us to examine a representation of how information in the universe is organized. And we can likely find out new things about the physical world around us. A critical question in this direction that needs to be answered is:
are we converging toward the universe’s information structure, or toward the structure of how humans represent information about the universe?
I think a major criticism AI for science, that so far has been somewhat valid, is that it has only ever reconstructed things we already know. It is great that we can have faster neural network based solutions for different physics, but what will it discover? (okay, new solutions to protein folding is a good one). The platonic hypothesis suggests that yes, it will discover something and that discovery may lead to new understanding about how the universe works.

Thanks for writing this, it clarifies alot. My Pilates flow needs embeddings.